PlanetScale に入門してみる
きっかけ
下記の記事を Qiita で拝見したことをきっかけに、初めて PlanetScale というサービスを知りました。 PlanetScaleというサーバレスDBが凄く勢いのあるサービスらしいのでQuick Startやってみた - Qiita
公式ページはこちら。
こちらのサービスは、公式のページに
The MySQL-compatible serverless database platform.
とある通り、サーバレスの MySQL DB のプラットフォームサービスです。
最初に取り上げた Qiita の記事にある通り、このサービスは、
などなど色々なメリットが存在している様です。
私は、現職で CI/CD 周りの管理や実装を行なっているのですが、その CI/CD のパイプラインの中に DB の仕組みを組み込めるという発想がなかったため、とても斬新で興味を持ったので、今回試してみました。
本記事の構成
- サービスの登録 ~ 初期動作まで
- PlanetScale の特徴をデモで実感
の 2 part でいきます。
サービスの登録 ~ 初期動作まで
サービス登録
まずは公式のページから、サービスに登録していきます。
画面に従って、新しくアカウントを作成するか、github 経由でアカウントを登録することができます。
サービスの外観 & 特徴
サービスへのアカウント登録が済むと早速ユーザページに進み、サービスの特徴をさらうことができる様になっています。サクッと理解するのに大変助かります。(UI も素敵!)

読み進めていくと、最初に少し記述した部分と重なりますが、下記の機能が特徴の様です。
- サーバレス DB
- オープンソースの Vitess を使用しており、数秒でスケーリング可能
- 組み込みのコネクションプーリングを使用できるので、自前で DB にコネクションプールの設定をする必要無し
- Data Branching
- ソースコードの様に扱うことが可能で、production 環境にあげる前に staging 環境へ schema の変更を行いテストを実装することができる
- ノンブロッキング処理で schema の変更が可能
- 安全に production 環境へデプロイできるので、CI/CD のパイプラインに組み込むことが容易
- Deploy request の作成
- git の PR の様に、schema 変更の差分を作成し、チームに対してレビューを依頼することが可能
- Deploy queue によるデプロイ
- deploy request が承認されると、deploy request が queue に追加され、queue に存在する deploy request に対するデプロイのタイムラインが作成される。これにより、コンフリクトが発生しないことを保証した状態で本番環境へのデプロイを実現する
- モニタリング
- トラフィックや read/write の I/O をグラフで表示し、DB をモニタリングすることが可能
軽くさらっただけでも、かなり魅力的な特徴が並べられていました。 特に、読んでいて以下の二点に魅力を感じました。
- Data Branching 機能のおかげで、DB の schema 単位で各環境の管理ができるところ(自分の経験では、各環境に DB サーバを配置し、そのサーバ毎に管理するのが普通だった)
- schema 変更の差分が PR の様な形式で見れること
DB の新規作成 & 動作確認
上述した PlanetScale の特徴を読み進めていくと、最後に DB を作成するリンクが現れます。 そこで、名前を入力して create ボタンを押すと、AWS の region を指定した後、DB がすぐに作成されます。
DB 作成後にダッシュボードに移動し、ここから色々機能を触ることができる様です。

価格について
ここで、不用意に課金されない様に、無料プランを確認しておきます (2022/09/13 現在)。
無料プランとしては、一つの organization に対して、
- 5GB のストレージ
- 10 億レコードの読み込み
- 1000 万レコードの書き込み
- 1 つの production ブランチの作成
- 1 つの development ブランチの作成
- コミュニティサポート
がついてる様です。
毎月、という単位ではないので、"継続して個人開発のサービスに組み込む" という運用は向かなそうですが、サービスを試してみるだけなら問題なさそうです。

動作確認
公式の quick start guide を参考に、table の作成からデータの挿入までを進めていきます。
table の作成
例に沿って、categories と products という table を作成していきます。
SQL は、PlanetScale の GUI 上に用意されている console から実行することが可能で、手軽に実行&動作確認ができます。
まずは、"Branches" タブをクリック -> "main" ブランチをクリック -> "Console" タブをクリック で、SQL を実行できる Console にまで移動します。
移動後に下記を実行し、対象の二つの table を作成します。
CREATE TABLE categories ( id int NOT NULL AUTO_INCREMENT PRIMARY KEY, name varchar(255) NOT NULL );
CREATE TABLE products ( id int NOT NULL AUTO_INCREMENT PRIMARY KEY, name varchar(255) NOT NULL, image_url varchar(255), category_id INT, KEY category_id_idx (category_id) );
下記コマンドで結果を確認できます。
SHOW TABLES;
ここまでを実行すると、Console 上で添付の写真の様になっており、正しく table が作成できたことがわかります。

データの挿入
続いては、先ほど作成した各 table にデータを挿入していきます。
categories にデータを挿入
INSERT INTO categories (name) VALUES ('Office supplies');
products にデータを挿入
INSERT INTO products (name, image_url, category_id) VALUES ('Ballpoint pen', 'https://example.com/500x500', '1');
それぞれのデータを確認

これで正しくデータを挿入できていることを確認できました。
NOTE: "Schem" タブへ行くと、これまでは何も表示されていなかったが、先ほど作成した二つの table が確認できます。

production ブランチへ反映
これまでの操作が終わると、main ブランチに対して、"categories" と "products" という二つの table が作成された状態になります。この main ブランチは、デフォルトで作成される development ブランチの一つのです。そのため、これを本番環境(production)ブランチに反映させて、本番デプロイを行う必要があります。
production ブランチへの反映は簡単で、"Overview" タブをクリック -> 添付写真のにある "Promote a branch to production" をクリックするだけです。

すると下記の様なブランチを指定する画面と共に "Promote branch" ボタンが現れるので、main ブランチを指定して、クリックします。

これで、本番環境(production branch)へのデプロイは完了です。 画像にもある通り、production branch は下記の三つの特徴を持っており、普通のブランチとは異なる扱いになっています。
- 直接 schema 変更ができない
- 高可用性
- 定期自動バックアップ
安全な運用ができる特徴をサービス自体が production 環境に付与してくれているので、そこに関して特別なルールを設けたり、仕組みを導入したりする必要がなく、大変便利だなと思いました。
以上で、一通りの新規作成から production の設定までを実行しました。 以降では、PlanetScale の特徴にそれぞれフォーカスして、実際の開発を想定したデモを行っていこうと思います。
PlanetScale の特徴をデモで実感
最初にあげた特徴のうち、気になるものをピックアップして、それぞれ動作させてみようと思います。
水平スケーリング
こちらについては、価格表にある通り、個人の無料プランでは試すことができませんでした。
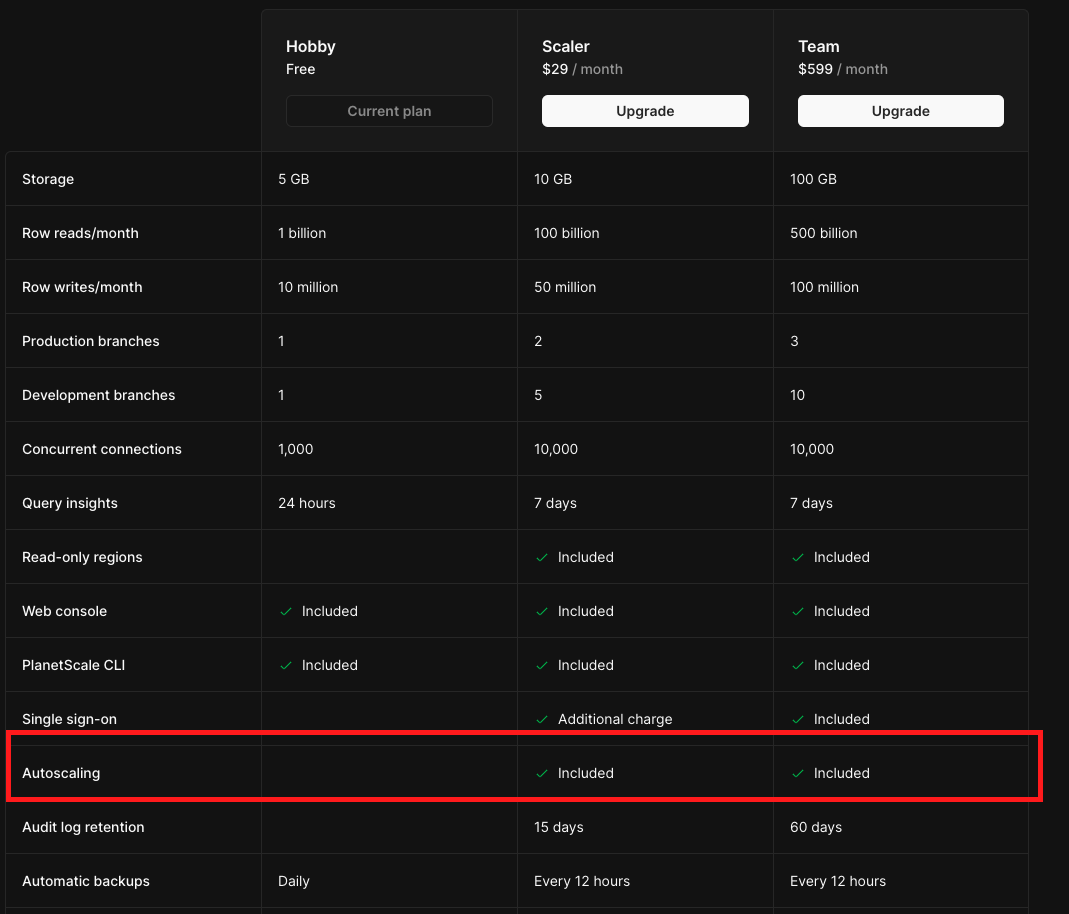
課金したプランから初めて Autoscaling の機能が付与される様です。 そのため、どれだけシームレスにスケーリングできるかなど実感できなかったのは残念です。
DB ブランチ
ここでは、branching 機能を体感してみようと思います。
新規ブランチ作成 ~ Deploy request 反映
まずは、新しい branch をダッシュボードから作成します。
新しいブランチを作成するには、"Overview" ページの右端の "New branch" ボタンをクリックし、添付写真のポップアップより、
- ブランチ名
- ベースとなるブランチ (今回は production の main ブランチ)
- AWS の region
を指定します。

また、このセクションでは、下記の公式の Node.js による接続デモをベースに進めていきます。
Connect a Node.js application to PlanetScale - Documentation - PlanetScale
新しいブランチを作成できたので、ブランチ上で新しく "user" table を作成し、データを挿入してみます。
table の作成
CREATE TABLE `users` ( `id` int NOT NULL AUTO_INCREMENT PRIMARY KEY, `email` varchar(255) NOT NULL, `first_name` varchar(255), `last_name` varchar(255) );
データの挿入
INSERT INTO `users` (id, email, first_name, last_name) VALUES (1, 'hp@example.com', 'Harry', 'Potter');
上記コマンドで、正しく table が作成され、テストデータが挿入できたことが確認できます。

それでは、この新しい schema に対して deploy request を作成していきます。
"Overview" ページのから、デプロイ先のブランチとコメントを入力して、"Create deploy request" をクリックします。

これで Deploy request が作成され、git の PR の様に、変更を加えた schema の差分を見ることができます。

これを "Summary" タブの "Deploy change" ボタンをクリックすることで反映させます。 反映が終わり、"main" ブランチについて schema を確認してみると、確かに "users" table が追加されていることが確認できます。

これにて、ブランチ機能を使って、schema の変更を反映させるフローが完了いたしました。
注意点としては、Deploy request では、schema の変更のみデプロイ対象になるので、データの実体は deploy されないことを念頭に置かないといけません。
NOTE: このデモでは、後続の疎通確認デモ内で、上述した "users" table のデータを使用したいので、production ではありますが、 "main" ブランチに対して console からデータの挿入を行いテストデータを準備します。
アプリケーションからの接続
続いて、上記 table へアクセスを行うアプリケーションの立ち上げを行います。 公式のページにサンプルの Node.js のアプリがあるので、そちらを clone してセットアップします。
git clone https://github.com/planetscale/express-example.git cd express-example npm install
ここで、一旦 PlanetScale のダッシュボードへ戻り、接続情報の設定を行います。 "Overview" ページの右端にある "Connect" ボタンをクリックし、接続設定ページへ遷移します。 そこでは、プルダウンで言語ごとの接続情報を選択することができるので、Node.js を選択します。
これにより、添付画像(password 等は赤く塗りつぶしています。)の様に、username と password が取得でき、それに対応した各設定ファイルごとの変数定義も入手することができます。

これを clone してきたサンプルのアプリに設定します。
私は、.env ファイルを作成し、DATABASE_URL をコピペしました。
これにて設定が全て完了したので、アプリを起動します。
node app.js
http://localhost:3000 でアプリが起動し、前半で作成した "users" に対するテストデータが取得できます。
[ { "id": 1, "email": "hp@example.com", "first_name": "Harry", "last_name": "Potter" } ]
CI/CD への組み込み
Github actions 経由で PlanetScale の CLI を起動することも可能な様です。
Using the PlanetScale CLI with GitHub Actions workflows
ただし、無料枠では、Data のコピーをとった development ブランチの作成ができないので、あまり有用性を感じるデモをできない状態です。
Data Branching™ - Documentation - PlanetScale
まとめ
これまでで、PlanetScale においてデータベースの作成 ~ DB のブランチングまでを実行し、アプリケーションからの疎通確認も行いました。残念ながら、このサービスの魅力のコアとなる部分は、無料枠ではなかなか体験することができませんでした。
上記を実行してみた感想としては、 * ブランチごとに接続設定ができない?(無料枠だから?)っぽいので、ブランチごとに環境を分ける使い方をしたいのにできなそう * もし有料枠ならブランチごとに環境を分けられたとして、接続情報を固定しないと運用するときにめんどくさいことになりそう * deploy request は有用そうだが、普通に .txt などに DML を記述して github なりでなんなりで管理する運用にすれば、同じ恩恵をタダで受けられそう * あまり CI/CD に組み込んで DB の schema を変更したいユースケースが思いつかなかったので、そこまで大きなメリットを感じなかった
という感想です。 当初の Qiita の記事を読んだ時は、良いことしかなさそうでしたが、やってみて初めて意外と使いどころが思いつかないことがわかりました。(私が未熟なだけの可能性も高いので、こんなのあるよ!って方いたらぜひ教えてくださいmm)
"サービス開発に携わりたい新卒向け プロダクトマネジメント論とFigma勉強会" に参加しました!
本記事は、2021 年 8 月 25 日に開催された、dely 株式会社主催の "サービス開発に携わりたい新卒向け プロダクトマネジメント論とFigma勉強会" に参加してみた感想記事になります。
本記事では、
- 勉強会の内容
- 所感
という順でお送りしたいと思います。
勉強会の内容
本勉強会は、タイトルにある通り
- 新卒に向けたプロダクトマネジメントの概要についての紹介
- Figma 初心者向けの Figma の使い方
の前編後編二本立てで構成されていました。
プロダクトマネジメント論パート
前編のプロダクトマネジメント論のパートでは、dely の CXO をされている 坪田 朋 さんという方が担当して、略歴、坪田さんの考えるプロダクトマネジメントとは、大事にしている信条、dely ではこのようにやっている!、などが語られました。
坪田さん曰く、プロダクトマネジメントとは、
- CEO の考えている理想の状態を汲み取って解釈し、
- 現状からその理想までをどうやって到達するかを考える
ことであるそうです。
下記の図のように、往々にして、プロダクトの現状だったり新規サービスのローンチなどのスタート地点は、理想の状態よりも低い位置に存在しています。

その時に、
- そもそも理想の状態はどうなったら達成しているのか?
- 理想まで辿り着くには何をしたらいいのか?
を考えるのがプロダクトマネジメントの仕事であるということです。
dely では、この "理想に到達する" 手段として、MVP (Minimum Viable Product) プロセスを採用しているようです。

画像下半分のように、最低限の価値のあるものを開発 & リリースし、そのサイクルを複数回行うことで理想の形に近づけていけます。
セッションでは、MVP プロセスを採用することのメリットとして、大きな不確実性の排除が可能であることも語られていました。
画像上半分のウォーターフォール型開発と呼ばれるプロセスでは、最後のステップでようやくプロダクトができるので、そこに到達するまでの開発上の問題だったり、そもそもプロダクトのデザインがイケてなかったりなど、理想の状況に到達するまでに大きな不確実性が発生してしまいます。
一方、MVP プロセスでは、理想に到達するまでに開発を小さなステップに分けて行うので、大きな不確実性を排除して、確度を上げて価値あるプロダクトを開発できるようになります。
また、MVP プロセスでは、各ステップでユーザにプロダクトが届けられるので、ユーザから随時フィードバックを受けることができます。 これによって、そもそもの理想が間違っていたので方向転換しよう!ということも可能になり、より素早く柔軟に価値あるプロダクトを届けることができるのも良い点です。
dely では、より素早く意思決定を行い効率的に開発を進めていくために、Squad 組織という組織体制を敷くよう変更したという話もありました。

日本でよくみるピラミッド図のような組織体制ではなく、チームを細分化し、それぞれが KPI に向かって独自の裁量を持って突き進んでいくという体制です。
これにより、意思決定がボトルネックとなる開発の遅れが解消できるだけでなく、担当者がプロダクトを自分ごととして捉えられるようになり、自走できるチーム作りも行えるというメリットがあるようです。
こちらの Squad 化については詳しく語られませんでしたが、後日共有いただいた坪田さんの note に詳細が書いてありますので、興味のある方はそちらをご覧ください。
開発体制をSquad化してきてわかってきたコツと課題|坪田 朋
Figma 使い方パート
こちらのパートでは、dely の 20 卒のデザイナーの遠藤さんという方が担当して、実際に Figma を使いながらデモを見せる形式で進めてくださいました。
内容は主に、
- ショートカットを体で覚えよう
- パーツは再利用しよう
- シェアするときはスクリーンショットと URL をシェアしよう
の三つに分かれており、それぞれで実際に Figma を触りながら、説明してくれました。
ショートカットを体で覚えよう
Figma の良いところは、サクッとデザインを作成できて、手軽にシェアできるところだと思います。 そのため、ショートカットキーを覚えて、デザイン作成するスピードを上げていくことはとても重要なスキルになります。
このパートでは、遠藤さんがライブデモとして、実際に Figma のロゴを手早く作ってくれました。 デザイナーさんの作成している姿を初めて見たので、ショートカットキーの大事さだったり、スピード感だったりを肌で感じることができました。
パーツは再利用しよう
Figma の二つ目の良いところは、他人が作成したデザインパーツを再利用できるところです。 ガンガン再利用して、クオリティの高いデザインを手早く作ることが可能になります。
このパートのデモでは、クラシルのレシピページのスクリーンショットを元に、レシピの量を人数分で動的に変化させられるデザインを作成していました。 こちらも、すごい早さでデザインが出来上がり、実践的なテクニックとして、とても有意義なデモでした。
また、クラシルでは、基本的な UI のパーツなどがみんなで利用できる場所に置かれているらしく、誰でも手軽にクラシルのページのデザインをクオリティ高くできるようです。
シェアするときはスクリーンショットと URL をシェアしよう
最後のパートでは、Figma を使ってチーム開発するときの Tips 的な内容になります。 Figma では URL をシェアするだけで、自分の作成したデザインを共同編集できるものとして共有することができます。 しかし、URL だけシェアしたのでは、例えば slack 上では、何があるのかパッとわかりません。 なので、そこのコミュニケーションコストを減らすためにも、URL のシェアと一緒に作成した Figma のスクリーンショットも添えてあげると良いようです。
所感
私は、新卒入社3年目のエンジニアなので、今回の勉強会の対象者ではなかったのですが、普段関わりのない領域の考え方に触れられてとても楽しく参加できました。 自社のプロダクトマネジメントの部署にいる人たちの様子を振り返ってみて、dely さんと比較してみて、同じように取り組んでいる部分とそうでない部分とが見えてきて、そういったところも面白かったです。
今回の勉強会は、新卒向けのものだったので込み入った話をしなかったのかなと思いますが、実際に Squad に分割する上での注意点であったり、MVP の単位はどうやって決めているのかなどのケーススタディも聴きたかったな思いました。
実際、考え方やメリットは分かっても、いざ実行に移すとうまくいかない、というのがこういった手法の常だと思うので、成功・失敗のケーススタディは是非聞いてみたいです。 なんなら他の会社も聞いてみたいので、他の会社が主催するプロダクトマネジメントに関する勉強会も参加したい欲が高まりました。
Figma のパートについては、入念に準備がされていたし、遠藤さんの発表がわかりやすかったので、満足度の高い勉強会でした。 実際にデザイナーさんがデザインを作っていく作業を見ることはなかなかないので、それだけでも貴重でしたし、尚且つ、作業する上での考え方とか気を付けるポイントも一緒に解説してくださって、個人的に Figma を触ってみようという気持ちになりました。 Figma の機能的にもまだまだアドバンスドな内容もありそうだったので、次回 Figma 勉強会が開催されることを期待しています!
Spring GraphQL を触ってみた
はじめに
2021 年 8 月 6 日に開催された JSUG勉強会 2021年その2 Spring GraphQLをとことん語る夕べ に参加し、Spring GraphQL について初めて学んできました。 新しく学べたことがたくさんあったので、復習も兼ねて、実際に手を動かして実装してみました。 このページで実装したリポジトリはこちらになります。
また勉強会で使用された資料やデモ実装はこちらの方の Github リポジトリにて公開されています。
Graph QL とは?
そもそも、この勉強会に参加してみて、初めて GraphQL というものを知りました。 GraphQL とは、API 用に設計されたクエリ言語で、API の速度、柔軟性、開発者にとっての使いやすさを向上させるために設計された1 ようです。 特徴2 としては、
- 型を定義して、それに対してクエリを実行する => データベースに依存しない
- 必要な型に対してのみクエリを実行できる => クライアントが必要なデータのみ取得可能
- 一度のリクエストで複数のリソースを取得できる => REST の場合はリソース毎にエンドポイントを用意して、それぞれにリクエストを投げる必要あり
- API をバージョンなしで進化させられる => クライアントは必要な型のみを定義してクエリを実行するため、新たなフィールドが型に追加されたとしても、クライアントにはなんの影響も出ない。もし、型のフィールドを削除する場合にも、deprecated アノテーションをつけるなど、対応策がある。
が挙げられます。
実装してみる
環境
- Java: 11
- Spring Boot: 2.5.3
- graphql-spring-boot-starter: 5.0.2
プロジェクト作成
プロジェクトは、Spring Initializer を使用して作成します。 group や artifact などは好きに設定して OK です。 Depedency には以下を追加しました。
これらに加えて、今回使用する Spring GraphQL の depedency を追加します。
<dependency>
<groupId>org.springframework.experimental</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
<version>1.0.0-M1</version>
</dependency>
<repositories>
<repository>
<id>spring-milestones</id>
<url>https://repo.spring.io/milestone</url>
</repository>
<repository>
<id>spring-snapshots</id>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
型の定義
まずは今回扱う型の定義を行います。
SpringBoot では、クラスパス上の graphql ディレクトリに存在する
.graphqls .graphql .gpl .gpls
を型定義の対象ファイルとして扱うので、src/main/resources/graphql 以下に型定義ファイルを作成します。
今回は、各ゲーム会社についてデータを作成しようと思うので、Company と Game という型を作っていきます。
type Game {
id: ID!
name: String!
companyName: String
kind: String
}
type Company {
companyId: ID!
name: String!
games: [Game!]!
}
type Query {
game(id: ID!): Game
games: [Game!]!
company(companyId: ID!): Company
companies: [Company!]!
}
type Mutation {
createCompany(companyId: ID!, name: String!): Company
createGame(id: ID!, name: String!, companyName: String!, kind: String!): Game
}
これらは GraphQL の文法になるので、詳細や他の文法については公式ページを見ていただくとして、今回使用した type XXX と type Query、type Mutation について簡単に説明します。
type XXX: type を用いて宣言を行うと、その名前の型を定義することができます。Java でいう class XXX としているようなものです。今回の例では、id, name, companyName, kind というフィールドを持つ Game 型と companyId, name, games というフィールドを持つ Company 型を定義したことになります。
それぞれのフィールドは フィールド名: データタイプ という形式で記述します。データタイプは、公式ページより、以下が指定できるようです。
- ID: The ID scalar type represents a unique identifier (= データを一意に特定するためのもの。SQL の主キー。)
- Int: A signed 32‐bit integer
- Float: A signed double-precision floating-point value
- String: A UTF‐8 character sequence.
- Boolean:
trueorfalse
type Query: これは特別な型宣言で、この Query type の中でデータを取得するときの query を宣言します。
type Mutation: これも特別な型宣言で、この Mutation type の中でデータを更新、作成、削除するときの query を宣言します。
データの挿入
今回はデモができれば良いだけなので、利便性を重視して、インメモリデータベースの h2 を使用します。 インメモリではありますが、設定次第で、作成したデータをファイルに保存して永続化ができるので、今回はそちらで対応します。
まずは、下記の SQL でテーブルを作成します。
-- GAME テーブルの作成
CREATE TABLE GAME(
ID INT PRIMARY KEY,
NAME VARCHAR(100) NOT NULL,
COMPANY_NAME VARCHAR(100) NOT NULL,
KIND VARCHAR(10)
);
-- COMPANY テーブルの作成
CREATE TABLE COMPANY(
COMPANY_ID INT PRIMARY KEY,
NAME VARCHAR(100) NOT NULL
);
次にテストデータを作成します。
-- GAME data INSERT INTO GAME (ID, NAME, COMPANY_NAME, KIND) VALUES(1, 'ドラゴンクエスト XI 過ぎ去りし時を求めて', 'SQUEA ENIX', 'RPG'); INSERT INTO GAME (ID, NAME, COMPANY_NAME, KIND) VALUES(2, 'FINAL FANTASY X', 'SQUEA ENIX', 'RPG'); INSERT INTO GAME (ID, NAME, COMPANY_NAME, KIND) VALUES(3, '桃太郎電鉄 ~昭和 平成 令和も定番!', 'ハドソン', 'ボードゲーム'); INSERT INTO GAME (ID, NAME, COMPANY_NAME, KIND) VALUES(4, 'マリオテニスエース', '任天堂', 'スポーツゲーム'); -- COMPANY data INSERT INTO COMPANY (COMPANY_ID, NAME) VALUES (1, 'SQUEA ENIX'); INSERT INTO COMPANY (COMPANY_ID, NAME) VALUES (2, 'ハドソン'); INSERT INTO COMPANY (COMPANY_ID, NAME) VALUES (3, '任天堂');
データを確認します。
SELECT * FROM GAME;

SELECT * FROM COMPANY;

画像の通りテストデータを作成することができました。
次は、このデータを取得するまでの流れを作成します。
データフェッチ部分の実装
まずは各 type に対応する Entity クラスを作成します。
// Company
@Entity
public class Company {
@Id
Integer companyId;
String name;
public Company() {
}
public Company(Integer companyId, String name) {
this.companyId = companyId;
this.name = name;
}
public Integer getCompanyId() {
return companyId;
}
public void setCompanyId(Integer companyId) {
this.companyId = companyId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
// Game
@Entity
public class Game {
@Id
Integer id;
String name;
String companyName;
String kind;
public Game() {
}
public Game(Integer id, String name, String companyName, String kind) {
this.id = id;
this.name = name;
this.companyName = companyName;
this.kind = kind;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getKind() {
return kind;
}
public void setKind(String kind) {
this.kind = kind;
}
}
次に、データをフェッチしてくる部分の実装です。
RuntimeWiringBuilderCustomizer クラスの customize メソッドをオーバーライドすることで実現できます。
@Component
public class GameDataWiring implements RuntimeWiringBuilderCustomizer {
private GameRepository gameRepository;
private CompanyRepository companyRepository;
public GameDataWiring(GameRepository gameRepository, CompanyRepository companyRepository) {
this.gameRepository = gameRepository;
this.companyRepository = companyRepository;
}
@Override
public void customize(RuntimeWiring.Builder builder) {
builder.type("Query", builder1 ->
builder1.dataFetcher("game", env -> {
Integer id = Integer.valueOf(env.getArgument("id"));
return gameRepository.findById(id);
})
.dataFetcher("games", env -> {
return gameRepository.findAll();
})
.dataFetcher("company", env -> {
Integer companyId = Integer.valueOf(env.getArgument("companyId"));
return companyRepository.findById(companyId);
})
.dataFetcher("companies", env -> {
return companyRepository.findAll();
})
);
builder.type("Company", builder1 ->
builder1.dataFetcher("games", env -> {
Company company = env.getSource();
return gameRepository.findByCompanyName(company.getName());
})
);
builder.type("Mutation", builder1 ->
builder1.dataFetcher("createCompany", env -> {
Integer companyId = Integer.valueOf(env.getArgument("companyId"));
String companyName = env.getArgument("name");
Company company = new Company();
company.setCompanyId(companyId);
company.setName(companyName);
return companyRepository.save(company);
})
.dataFetcher("createGame", env -> {
Integer id = Integer.valueOf(env.getArgument("id"));
String gameName = env.getArgument("name");
String companyName = env.getArgument("companyName");
String gameKind = env.getArgument("kind");
Game game = new Game();
game.setId(id);
game.setName(gameName);
game.setCompanyName(companyName);
game.setKind(gameKind);
return gameRepository.save(game);
})
);
}
}
ポイントとしては、最初に定義した型に対する dataFetcher を全て定義する ということです。
今回の例では、"Query" として定義した中に、"game"、"games"、"company"、"companies" という子要素を定義しました。
そのため、builder に対して "Query" を type メソッドで宣言し、その中でそれぞれの子要素に対して対応するデータ処理を書いていきます。
"game" の場合は、引数として与えられた id を基に、DB 上からレコードを引っ張ってくることになるので、return で gameRepository.findById(id) を返しています。
一方で、Company を呼び出した際には、"games" が呼び出されて、その会社が販売している Game データを紐付けます。このような場合には、builder に対して "Company" を type メソッドで宣言し、対応する Game データを取得します。
このようにして、自分が定義したデータ型に対して、全ての要素に対応するデータ取得方法を実装していきます。
実行
ここまでで実行までの準備が完了です。
REST や Controlller といった実装に慣れている方は少し戸惑うかもしれないのですが、GraphQL の場合は、デフォルトで /graphql に対して POST エンドポイントがマッピングされていて、特に Controller の設定をしなくても大丈夫です。これに加えて、/graphiql という GUI のパスもデフォルトで設定されているので、容易に動作検証を行うことができます。
では、それぞれのクエリについて動作を見ていきましょう。
game(id: ID)
query {
game(id: 1) {
id
name
companyName
kind
}
}

games
query {
games {
id
name
companyName
kind
}
}

copmany(id: ID)
query {
company(companyId: 1) {
companyId
name
games {
id
name
kind
}
}
}
対応する Game データの一覧が取得できているのがわかります。

companies
query {
companies {
name
games{
id
name
kind
}
}
}

Mutation も同様にクエリを構築して、リクエストを投げることができます。
createCompany
mutation {
createCompany(companyId: 4, name: "KONAMI") {
companyId
name
}
}

H2 database 上でも確認してみます。
 正しくデータが追加されていることがわかります。
正しくデータが追加されていることがわかります。
createGame
mutation {
createGame(id:5, name: "パワフルプロ野球 2020", companyName: "KONAMI", kind: "スポーツゲーム"){
id
name
kind
}
}
 こちらも、H2 database 上でも確認してみます。
こちらも、H2 database 上でも確認してみます。
 正しくデータが追加されていることがわかります。
正しくデータが追加されていることがわかります。
まとめ
この記事では、Spring GraphQL を使用して、簡単な Query と Mutation を作成してみました。 実際に実装してみた感想としては、GraphQL に関わる箇所の実装がそこまで複雑じゃないのに、柔軟なエンドポイントを作成できたので、とても利便性が高いと感じました。 特にクライアントが欲しいデータのみリクエストできるところが、魅力的に感じました。
ただ、実際に業務で使用するとなると、
- エンドポイントのセキュリティはどうするか => Spring Security を使えば実装できるようだが、結構込み入った話になってくるので、ここに実装の工数が多くかかりそう
- データが大量にある場合に、どうやってパフォーマンスを上げるか => DataLoader を使うことでパフォーマンスの向上を図れるが、複雑なデータ型だったりした場合にはうまくいかないかも?
のあたりをどうするか要検討ポイントだと感じました。
ただ、GraphQL でうまくいかなそうなところは、Spring MVC をベースとした REST API を組んだりするなど、方向転換が容易なところが Spring GraphQL の大きな魅力なのかなとも思いました。
参考文献
*1: GraphQL とは - 概要、特徴、メリット・デメリット | Red Hat
*2: https://backpaper0.github.io/spring-graphql-introduction/