PlanetScale に入門してみる
きっかけ
下記の記事を Qiita で拝見したことをきっかけに、初めて PlanetScale というサービスを知りました。 PlanetScaleというサーバレスDBが凄く勢いのあるサービスらしいのでQuick Startやってみた - Qiita
公式ページはこちら。
こちらのサービスは、公式のページに
The MySQL-compatible serverless database platform.
とある通り、サーバレスの MySQL DB のプラットフォームサービスです。
最初に取り上げた Qiita の記事にある通り、このサービスは、
などなど色々なメリットが存在している様です。
私は、現職で CI/CD 周りの管理や実装を行なっているのですが、その CI/CD のパイプラインの中に DB の仕組みを組み込めるという発想がなかったため、とても斬新で興味を持ったので、今回試してみました。
本記事の構成
- サービスの登録 ~ 初期動作まで
- PlanetScale の特徴をデモで実感
の 2 part でいきます。
サービスの登録 ~ 初期動作まで
サービス登録
まずは公式のページから、サービスに登録していきます。
画面に従って、新しくアカウントを作成するか、github 経由でアカウントを登録することができます。
サービスの外観 & 特徴
サービスへのアカウント登録が済むと早速ユーザページに進み、サービスの特徴をさらうことができる様になっています。サクッと理解するのに大変助かります。(UI も素敵!)

読み進めていくと、最初に少し記述した部分と重なりますが、下記の機能が特徴の様です。
- サーバレス DB
- オープンソースの Vitess を使用しており、数秒でスケーリング可能
- 組み込みのコネクションプーリングを使用できるので、自前で DB にコネクションプールの設定をする必要無し
- Data Branching
- ソースコードの様に扱うことが可能で、production 環境にあげる前に staging 環境へ schema の変更を行いテストを実装することができる
- ノンブロッキング処理で schema の変更が可能
- 安全に production 環境へデプロイできるので、CI/CD のパイプラインに組み込むことが容易
- Deploy request の作成
- git の PR の様に、schema 変更の差分を作成し、チームに対してレビューを依頼することが可能
- Deploy queue によるデプロイ
- deploy request が承認されると、deploy request が queue に追加され、queue に存在する deploy request に対するデプロイのタイムラインが作成される。これにより、コンフリクトが発生しないことを保証した状態で本番環境へのデプロイを実現する
- モニタリング
- トラフィックや read/write の I/O をグラフで表示し、DB をモニタリングすることが可能
軽くさらっただけでも、かなり魅力的な特徴が並べられていました。 特に、読んでいて以下の二点に魅力を感じました。
- Data Branching 機能のおかげで、DB の schema 単位で各環境の管理ができるところ(自分の経験では、各環境に DB サーバを配置し、そのサーバ毎に管理するのが普通だった)
- schema 変更の差分が PR の様な形式で見れること
DB の新規作成 & 動作確認
上述した PlanetScale の特徴を読み進めていくと、最後に DB を作成するリンクが現れます。 そこで、名前を入力して create ボタンを押すと、AWS の region を指定した後、DB がすぐに作成されます。
DB 作成後にダッシュボードに移動し、ここから色々機能を触ることができる様です。

価格について
ここで、不用意に課金されない様に、無料プランを確認しておきます (2022/09/13 現在)。
無料プランとしては、一つの organization に対して、
- 5GB のストレージ
- 10 億レコードの読み込み
- 1000 万レコードの書き込み
- 1 つの production ブランチの作成
- 1 つの development ブランチの作成
- コミュニティサポート
がついてる様です。
毎月、という単位ではないので、"継続して個人開発のサービスに組み込む" という運用は向かなそうですが、サービスを試してみるだけなら問題なさそうです。

動作確認
公式の quick start guide を参考に、table の作成からデータの挿入までを進めていきます。
table の作成
例に沿って、categories と products という table を作成していきます。
SQL は、PlanetScale の GUI 上に用意されている console から実行することが可能で、手軽に実行&動作確認ができます。
まずは、"Branches" タブをクリック -> "main" ブランチをクリック -> "Console" タブをクリック で、SQL を実行できる Console にまで移動します。
移動後に下記を実行し、対象の二つの table を作成します。
CREATE TABLE categories ( id int NOT NULL AUTO_INCREMENT PRIMARY KEY, name varchar(255) NOT NULL );
CREATE TABLE products ( id int NOT NULL AUTO_INCREMENT PRIMARY KEY, name varchar(255) NOT NULL, image_url varchar(255), category_id INT, KEY category_id_idx (category_id) );
下記コマンドで結果を確認できます。
SHOW TABLES;
ここまでを実行すると、Console 上で添付の写真の様になっており、正しく table が作成できたことがわかります。

データの挿入
続いては、先ほど作成した各 table にデータを挿入していきます。
categories にデータを挿入
INSERT INTO categories (name) VALUES ('Office supplies');
products にデータを挿入
INSERT INTO products (name, image_url, category_id) VALUES ('Ballpoint pen', 'https://example.com/500x500', '1');
それぞれのデータを確認

これで正しくデータを挿入できていることを確認できました。
NOTE: "Schem" タブへ行くと、これまでは何も表示されていなかったが、先ほど作成した二つの table が確認できます。

production ブランチへ反映
これまでの操作が終わると、main ブランチに対して、"categories" と "products" という二つの table が作成された状態になります。この main ブランチは、デフォルトで作成される development ブランチの一つのです。そのため、これを本番環境(production)ブランチに反映させて、本番デプロイを行う必要があります。
production ブランチへの反映は簡単で、"Overview" タブをクリック -> 添付写真のにある "Promote a branch to production" をクリックするだけです。

すると下記の様なブランチを指定する画面と共に "Promote branch" ボタンが現れるので、main ブランチを指定して、クリックします。

これで、本番環境(production branch)へのデプロイは完了です。 画像にもある通り、production branch は下記の三つの特徴を持っており、普通のブランチとは異なる扱いになっています。
- 直接 schema 変更ができない
- 高可用性
- 定期自動バックアップ
安全な運用ができる特徴をサービス自体が production 環境に付与してくれているので、そこに関して特別なルールを設けたり、仕組みを導入したりする必要がなく、大変便利だなと思いました。
以上で、一通りの新規作成から production の設定までを実行しました。 以降では、PlanetScale の特徴にそれぞれフォーカスして、実際の開発を想定したデモを行っていこうと思います。
PlanetScale の特徴をデモで実感
最初にあげた特徴のうち、気になるものをピックアップして、それぞれ動作させてみようと思います。
水平スケーリング
こちらについては、価格表にある通り、個人の無料プランでは試すことができませんでした。
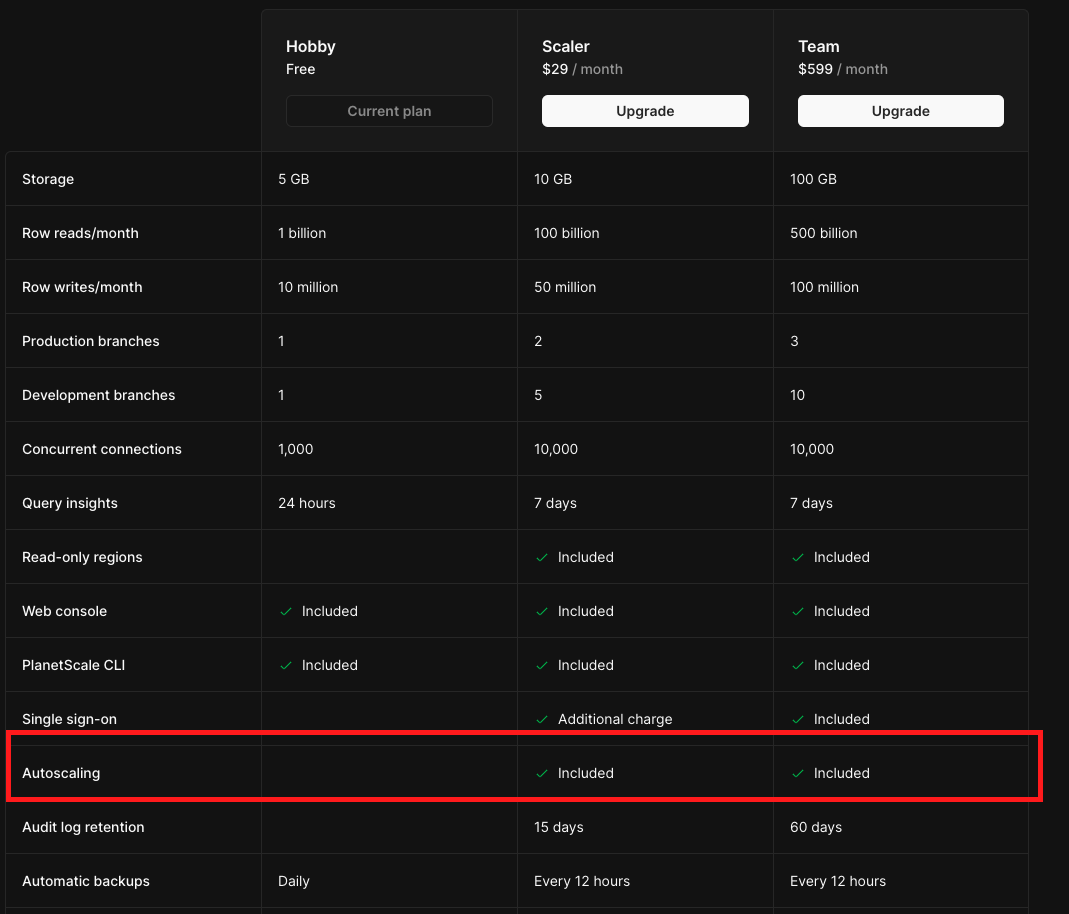
課金したプランから初めて Autoscaling の機能が付与される様です。 そのため、どれだけシームレスにスケーリングできるかなど実感できなかったのは残念です。
DB ブランチ
ここでは、branching 機能を体感してみようと思います。
新規ブランチ作成 ~ Deploy request 反映
まずは、新しい branch をダッシュボードから作成します。
新しいブランチを作成するには、"Overview" ページの右端の "New branch" ボタンをクリックし、添付写真のポップアップより、
- ブランチ名
- ベースとなるブランチ (今回は production の main ブランチ)
- AWS の region
を指定します。

また、このセクションでは、下記の公式の Node.js による接続デモをベースに進めていきます。
Connect a Node.js application to PlanetScale - Documentation - PlanetScale
新しいブランチを作成できたので、ブランチ上で新しく "user" table を作成し、データを挿入してみます。
table の作成
CREATE TABLE `users` ( `id` int NOT NULL AUTO_INCREMENT PRIMARY KEY, `email` varchar(255) NOT NULL, `first_name` varchar(255), `last_name` varchar(255) );
データの挿入
INSERT INTO `users` (id, email, first_name, last_name) VALUES (1, 'hp@example.com', 'Harry', 'Potter');
上記コマンドで、正しく table が作成され、テストデータが挿入できたことが確認できます。

それでは、この新しい schema に対して deploy request を作成していきます。
"Overview" ページのから、デプロイ先のブランチとコメントを入力して、"Create deploy request" をクリックします。

これで Deploy request が作成され、git の PR の様に、変更を加えた schema の差分を見ることができます。

これを "Summary" タブの "Deploy change" ボタンをクリックすることで反映させます。 反映が終わり、"main" ブランチについて schema を確認してみると、確かに "users" table が追加されていることが確認できます。

これにて、ブランチ機能を使って、schema の変更を反映させるフローが完了いたしました。
注意点としては、Deploy request では、schema の変更のみデプロイ対象になるので、データの実体は deploy されないことを念頭に置かないといけません。
NOTE: このデモでは、後続の疎通確認デモ内で、上述した "users" table のデータを使用したいので、production ではありますが、 "main" ブランチに対して console からデータの挿入を行いテストデータを準備します。
アプリケーションからの接続
続いて、上記 table へアクセスを行うアプリケーションの立ち上げを行います。 公式のページにサンプルの Node.js のアプリがあるので、そちらを clone してセットアップします。
git clone https://github.com/planetscale/express-example.git cd express-example npm install
ここで、一旦 PlanetScale のダッシュボードへ戻り、接続情報の設定を行います。 "Overview" ページの右端にある "Connect" ボタンをクリックし、接続設定ページへ遷移します。 そこでは、プルダウンで言語ごとの接続情報を選択することができるので、Node.js を選択します。
これにより、添付画像(password 等は赤く塗りつぶしています。)の様に、username と password が取得でき、それに対応した各設定ファイルごとの変数定義も入手することができます。

これを clone してきたサンプルのアプリに設定します。
私は、.env ファイルを作成し、DATABASE_URL をコピペしました。
これにて設定が全て完了したので、アプリを起動します。
node app.js
http://localhost:3000 でアプリが起動し、前半で作成した "users" に対するテストデータが取得できます。
[ { "id": 1, "email": "hp@example.com", "first_name": "Harry", "last_name": "Potter" } ]
CI/CD への組み込み
Github actions 経由で PlanetScale の CLI を起動することも可能な様です。
Using the PlanetScale CLI with GitHub Actions workflows
ただし、無料枠では、Data のコピーをとった development ブランチの作成ができないので、あまり有用性を感じるデモをできない状態です。
Data Branching™ - Documentation - PlanetScale
まとめ
これまでで、PlanetScale においてデータベースの作成 ~ DB のブランチングまでを実行し、アプリケーションからの疎通確認も行いました。残念ながら、このサービスの魅力のコアとなる部分は、無料枠ではなかなか体験することができませんでした。
上記を実行してみた感想としては、 * ブランチごとに接続設定ができない?(無料枠だから?)っぽいので、ブランチごとに環境を分ける使い方をしたいのにできなそう * もし有料枠ならブランチごとに環境を分けられたとして、接続情報を固定しないと運用するときにめんどくさいことになりそう * deploy request は有用そうだが、普通に .txt などに DML を記述して github なりでなんなりで管理する運用にすれば、同じ恩恵をタダで受けられそう * あまり CI/CD に組み込んで DB の schema を変更したいユースケースが思いつかなかったので、そこまで大きなメリットを感じなかった
という感想です。 当初の Qiita の記事を読んだ時は、良いことしかなさそうでしたが、やってみて初めて意外と使いどころが思いつかないことがわかりました。(私が未熟なだけの可能性も高いので、こんなのあるよ!って方いたらぜひ教えてくださいmm)